Speed, caching, and the 40x cost wall

This is mid-thought, mid-evaluation, mid-engineering. Posting it because writing it out helps me think.
We have been running the RapidNative agent on Cerebras for a while now. The speed is unreal. GLM 4.7 streaming on Cerebras is the first inference experience that genuinely feels like the future. It is hard to go back.
But this week I sat down with the cost numbers and the math hit different.
The agent we started with
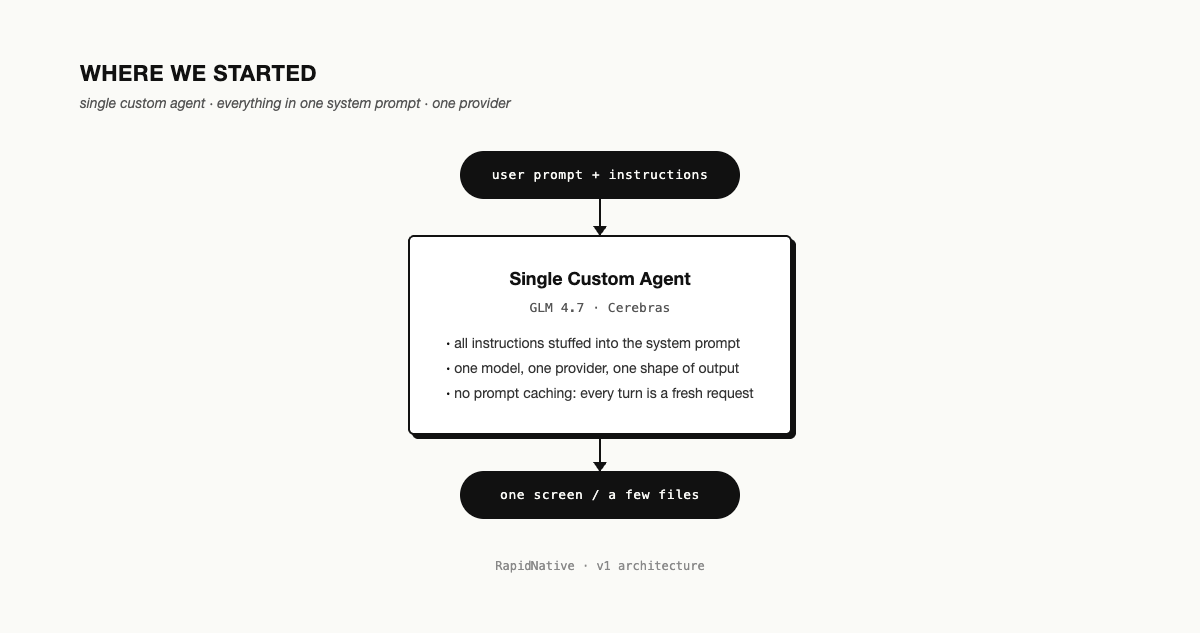
When RapidNative was generating one component at a time, the agent was simple. One model. One system prompt with all the instructions. One screen out, maybe a couple of files. We could hold the whole thing in our heads.
It stopped fitting fast. Real apps need plan mode, sub-agents that handle specific sub-tasks, MCP servers, skills you can compose. We were building all of that ourselves and the system was getting noisy.
Where the industry landed
Around the same time, I noticed Claude Code, OpenCode, and Flue (the new headless thing from the creator of Astro) had all converged on the same shape. Skills. Sub-agents. Plan mode. MCP. Whatever the next standard for agent runtimes ends up being, this is what it currently looks like.
Our custom thing was a worse version of it. Time to stop reinventing and start adopting.
The cost wall
Here is where it got interesting. Cerebras does not currently support prompt caching. In a coding session like the one RapidNative or OpenCode runs, every turn re-sends the entire conversation history. With caching, you only pay for the new tokens on each turn. Without it, you pay for everything, every turn.
The number we are seeing for the same model (GLM 4.7) on a provider with caching versus Cerebras without it: about 40x in token-cost savings, once you have a few turns into a session.
Yeah. 40x.
Speed matters. But not 40x.
The pivot we are evaluating
The pivot we are trying right now is to split the agent into a main agent and a screen-generation sub-agent, while keeping both halves on Cerebras.
Main agent runs GPT OSS 120B on Cerebras. About 5-6x cheaper per token than GLM 4.7 on the same provider. The cache-miss problem still bites because Cerebras still does not cache, but the cheaper per-token rate softens the blow on long-running conversation context.
Screen-gen sub-agent stays on GLM 4.7 on Cerebras. Short context, single-shot output. The speed of Cerebras is the entire point here, and the cache-miss problem does not bite hard when there is no long history to re-send.
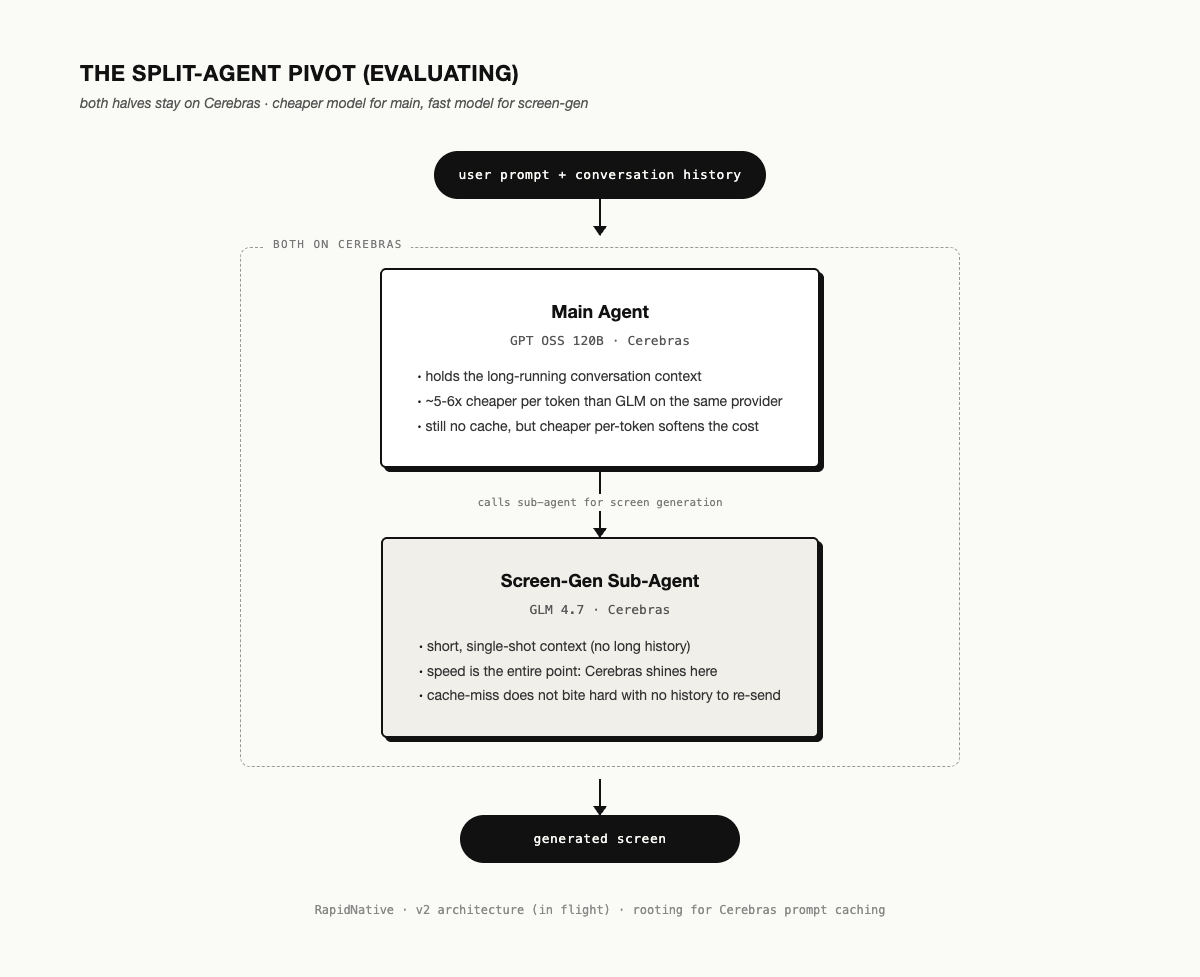
Different models for different sub-tasks. Inference is starting to look more like a router than a single endpoint, even when both halves stay on the same provider.
What we are actually rooting for
The plan is not to leave Cerebras. The plan is to use them where their speed is the entire point, and to soften the long-context cost with a cheaper model until they ship caching.
The thing we are most rooting for is Cerebras adding prompt caching. That single change closes the 40x gap entirely and makes this whole architectural exercise mostly moot for us. Until then, the cheaper-model-on-the-same-provider workaround is what we are evaluating.
If you have shipped something like this and learned something I should know, I would love to hear it.